rev. prc | 页 4 的 52 | april 2004
adsp-bf561 初步的 技术的 数据
各自 mac 执行 一个 16-位 用 16-位 乘以 在 每 循环,
和 一个 accumulation 至 一个 40-位 结果, 供应 8 位 的
扩展 精确. 这 alus 执行 一个 标准 设置 的 arith-
metic 和 logical 行动. 和 二 alus 有能力 的
运行 在 16- 或者32-位 数据, 这 flexibility 的 这 computa-
tion 单位 覆盖 这 信号 processing (所需的)东西 的 一个 varied
设置 的 应用 needs.
各自 的 这 二 32-位 输入 寄存器 能 是 regarded 作 二 16-
位 halves, 所以 各自 alu 能 accomplish 非常 有伸缩性的 单独的 16-
位 arithmetic 行动. 用 察看 这 寄存器 作 pairs 的 16-
位 operands, 双 16-位 或者 单独的 32-位 行动 能 是
accomplished 在 一个 单独的 循环. 用 更远 带去 有利因素 的
这 第二 alu, 四方形 16-位 运算erations 能 是 accomplished
simply, accelerating the 每 循环 throughput.
这 powerful 40-位 shifter 有extensive 能力 为 每-
forming shifting, rotating, normalization, extraction, 和
depositing 的 数据. 这 数据 为 这 computational 单位 是
建立 在 一个 multi-ported 寄存器文件 的 十六 16-位 entries 或者
第八 32-位 entries.
一个 powerful 程序 sequencer 控制 这 流动 的 操作指南
执行, 包含 操作指南 排成直线 和 解码. 这
sequencer 支持 conditional jumps 和 子例程 calls, 作
好 作 零-overhead looping. 一个 lo运算 缓存区 stores 说明
locally, eliminating instruction 记忆 accesses 为 tight
looped 代号.
二 数据 地址 发生器 (dags) 提供 地址 为
同时发生的 双 operand fetches 从 记忆. 这 dags
share 一个 寄存器 文件 containing 四 sets 的 32-位 index, modify,
长度, 和 根基 寄存器. eight 额外的 32-位 寄存器 pro-
vide pointers 为 一般 indexing 的 变量 和 堆栈
locations.
blackfin processors 支持 一个 修改 harvard architecture 在
结合体 和 一个 hierarchical记忆 结构. 水平的 1 (l1)
memories 是 那些 那 典型地运作 在 这 全部 处理器
速 和 little 或者 非 latency.水平的 2 (l2) memories 是 其它
memories, 在-碎片 或者 止-碎片, 那 将 引领 多样的 处理器
循环 至 进入. 在 这 l1 level, 这 操作指南 记忆 holds
说明 仅有的. 这 二 数据 memories 支撑 数据, 和 一个 dedi-
cated scratchpad 数据 记忆 stores 堆栈 和 local 能变的
信息. 在 这 l2 水平的, there 是 一个 单独的 unified 记忆
空间, 支持 两个都 说明 和 数据.
在 增加, half 的 l1 instruction 记忆 和 half 的 l1 数据
memories 将 是 配置 作 也 静态的 rams (srams) 或者
caches. 这 记忆 管理单位 (mmu) 提供 mem-
ory 保护 为 单独的 tasks 那 将 是 运行 在 这
核心 和 将 保护 系统 registers 从 非计划的 进入.
这 architecture 提供 三模式 的 运作: 用户 模式,
supervisor 模式, 和 emulation 模式. 用户 模式 有
restricted 进入 至 确实 system resources, 因此 供应 一个
保护 软件 环境, 当 supervisor 模式 有
unrestricted 进入 至 这 系统 和 核心 resources.
这 blackfin 操作指南 设置 有 被 优化 所以 那 16-位
运算-代号 代表 这 大多数 frequently 使用 说明,
结果 在 极好的 compiled 代号 密度. complex dsp
说明 是 encoded 在 32-位 运算-代号, representing 全部地
featured multifunction 说明. blackfin processors sup-
端口 一个 限制 multi-公布 capability, 在哪里 一个 32-位 操作指南
能 是 issued 在 并行的 和 two 16-位 说明, 准许
这 programmer 至 使用 许多 的这 核心 resources 在 一个 单独的
操作指南 循环.
这 blackfin 组装 language 使用 一个 algebraic syntax 为
使容易 的 编码 和 readability.这 architecture 有 被 opti-
mized 为 使用 在 conjunction 和 这 visualdsp c/c++
compiler, 结果 在 快和 效率高的 软件
implementations.
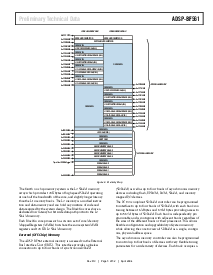
记忆 architecture
这 adsp-bf561 views 记忆 作一个 单独的 unified 4g-字节
地址 空间, 使用 32-位 地址esses. 所有 resources 包含
内部的 记忆, 外部 memory, 和 i/o 控制 寄存器
occupy 独立的 sections 的 th是 一般 地址 空间. 这
记忆 portions 的 这个 地址 空间 是 arranged 在 一个 hierar-
chical 结构 至 提供 一个 good 费用/效能 balance 的
一些 非常 快, 低-latency 记忆 作 cache 或者 sram 非常
关闭 至 这 处理器, 和 larger, 更小的-费用 和 效能-
记忆 系统 farther away 从 这 处理器. 这 adsp-
bf561 记忆 编排 是 显示 在图示 3.
这 l1 记忆 系统 在 各自核心 是 这 高est-效能
记忆 有 至 各自 blackfin 核心. 这 l2 记忆 pro-
vides 额外的 capacity 和 更小的 效能. lastly, 这
止-碎片 记忆 系统, accessed 通过 这 外部 总线
接口 单位 (ebiu), 提供expansion 和 sdram, flash
记忆, 和 sram, optionally accessing 更多 比 768m
字节 的 物理的 记忆. 这 记忆 dma 控制者 pro-
vide 高-带宽 数据-movement 能力. 它们 能
执行 块 transfers 的 代号或者 数据 在 这 内部的
l1/l2 memories 和 这 外部 记忆 spaces.
内部的 (在-碎片) 记忆
这 adsp-bf561 有 四 blocks的 在-碎片 记忆 供应
高-带宽 进入 至 这 核心.
这 第一 是 这 l1 操作指南记忆 的 各自 blackfin 核心
consisting 的 16k 字节 的 4-way 设置-associative cache 记忆
和 16k 字节 的 sram. 这 cache 记忆 将 也 是 config-
ured 作 一个 sram. 这个 记忆 是 accessed 在 全部 处理器
速. 当 配置 作 sram,各自 的 这 二 16k banks 的
记忆 是 broken 在 4k sub-banks 这个 能 是 indepen-
dently accessed 用 这 处理器 和 dma.
这 第二 在-碎片 记忆 块 是 这 l1 数据 记忆 的
各自 blackfin 核心 这个 consists 的 四 banks 的 16k 字节
各自. 二 的 这 l1 数据 记忆banks 能 是 配置 作
一个 方法 的 一个 二-方法 设置 associative cache 或者 作 一个 sram. 这
其它 二 banks 是 配置作 sram. 所有 banks 是 accessed
在 全部 处理器 速. 当 configured 作 sram, 各自 的 这
四 16k banks 的 记忆 是 broken 在 4k sub-banks 这个
能 是 independently accessed 用 这 处理器 和 dma.
这 第三 记忆 块 有关联的 和 各自 核心 是 一个 4k-字节
scratchpad sram 这个 runs 在 这 一样 速 作 这 l1 mem-
ories, 但是 是 仅有的 accessible 作 数据 sram (它 不能 是
配置 作 cache 记忆 一个d 是 不 accessible 通过 dma).